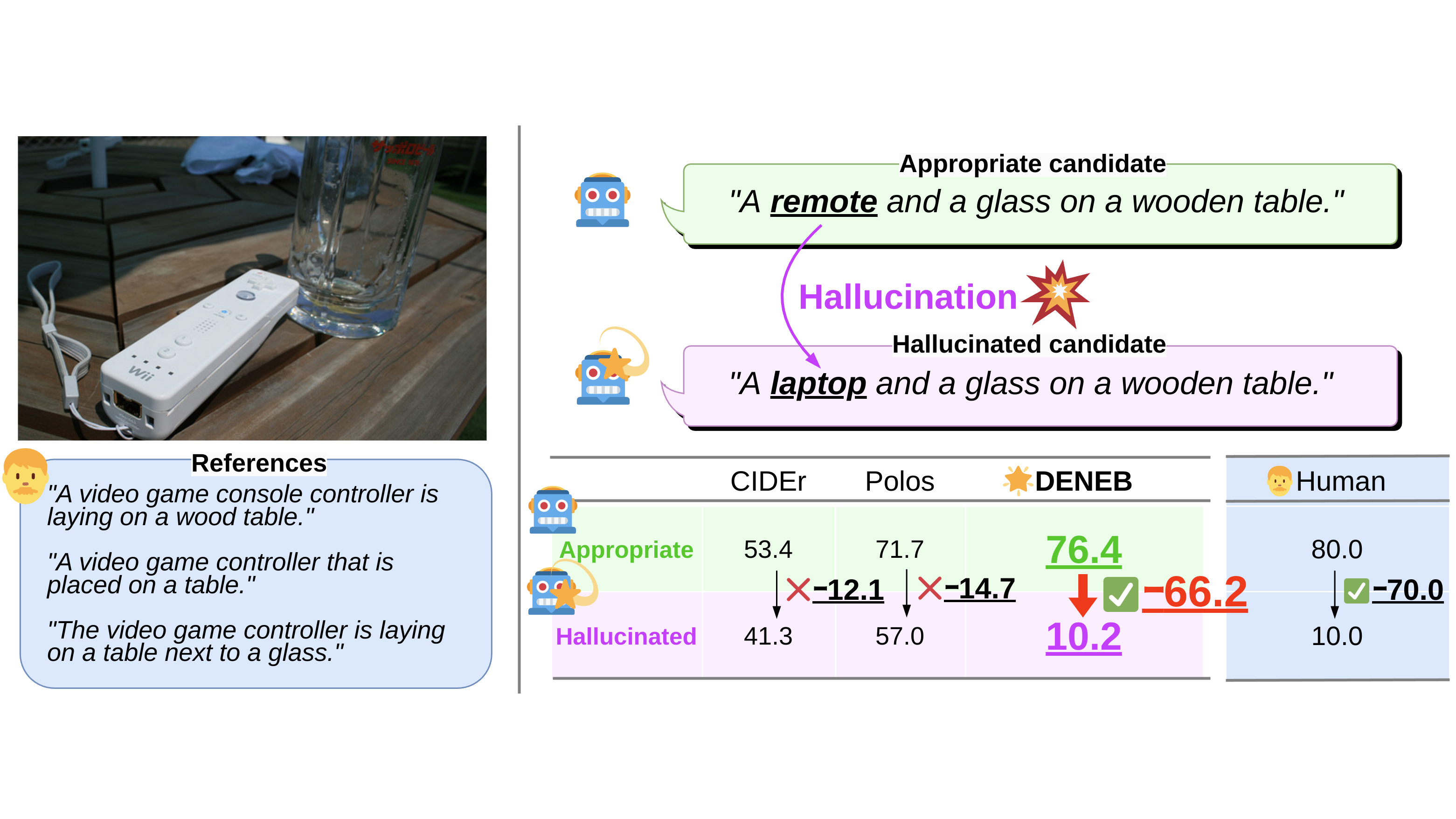
We address the challenge of developing automatic evaluation metrics for image captioning, with a
particular focus on the robustness against hallucinations. Existing metrics often inadequately
handle hallucinations, primarily due to their limited ability to compare candidate captions with
multifaceted reference captions. To address this shortcoming, we propose DENEB, a novel
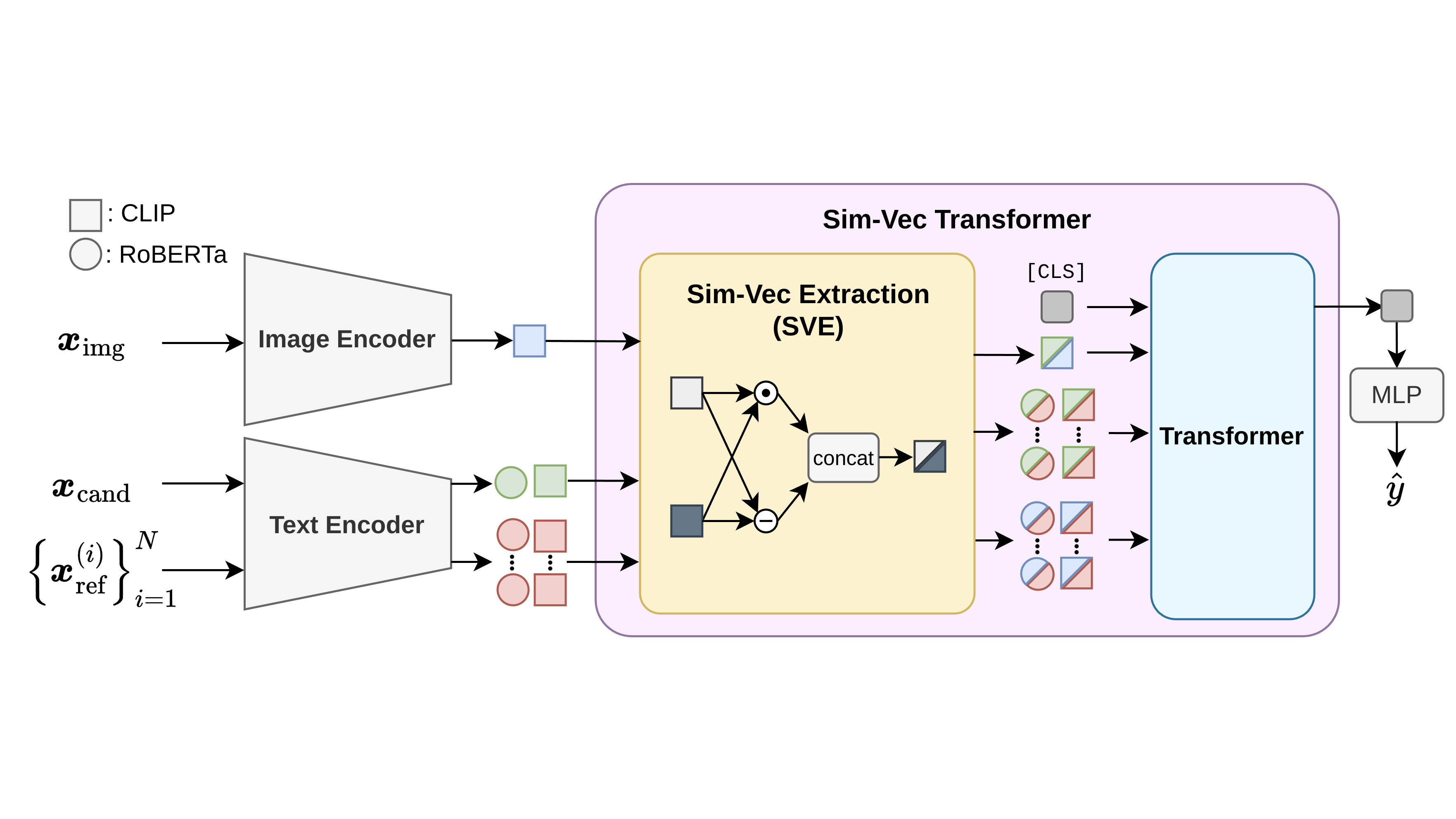
supervised automatic evaluation metric specifically robust against hallucinations. DENEB incorporates the
Sim-Vec Transformer, a mechanism that processes multiple references simultaneously, thereby efficiently
capturing the similarity among an image, a candidate caption, and reference captions. Furthermore, to
train DENEB, we construct the Nebula dataset, a diverse and balanced dataset comprising 32,978
images, paired with human judgments provided by 805 annotators. We achieved state-of-the-art
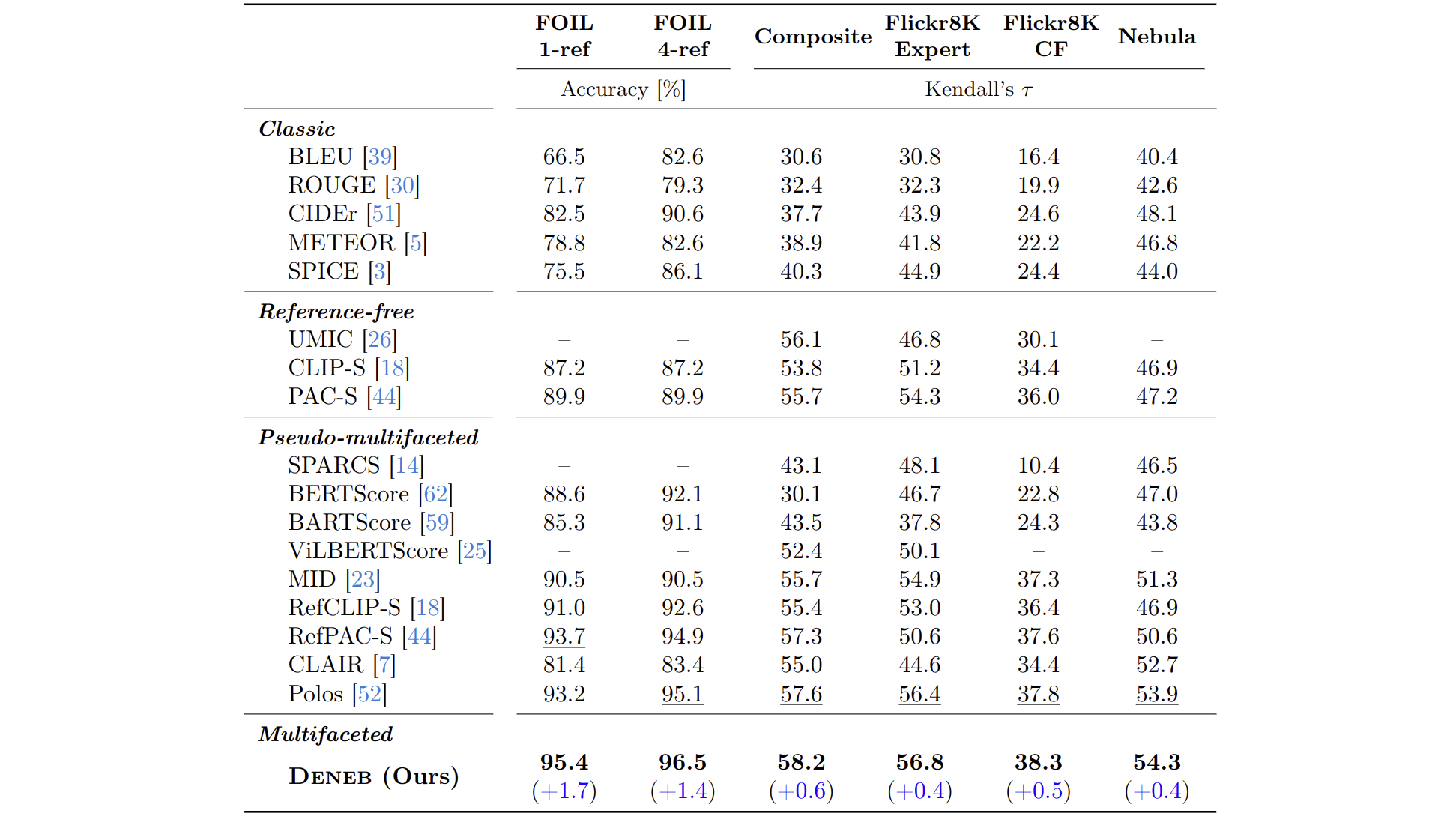
performance on FOIL, Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and PASCAL-50S, thereby
demonstrating its effectiveness and robustness against hallucinations.